
EDIT – Extracting Disaster Information from Text – or – Editing Disaster scenarios with Information extracted from Text – is a methodology to threat textual information extracted from web, originated by non-expert users and referring to the occurrence of a disaster event.
The project is born from a collaboration between CIMA Foundation (Italy) and the Nottingham Geospatial Institute (NGI) (United Kingdom).
The main goal is the development of a multi-perspective scenario of damage or potential risk using information from non-authoritative data ( i.e. online news, social media, photos, videos) collected during a disaster. The project represents a new contribute to the vision of scenarios and it is focused on the possibility of mosaicking real-time information from heterogeneous sources.
Components and information that are harvested are the ones most relevant in emergency management, during preparedness, response or post event phases, depending on the type of risk and expected damage.
Effective emergency management requires access to tools that can process data and quickly produce maps to analyze impacted areas and effects: it is vital to read information in a common language and in a harmonized environment.
When official data are not available, non-authoritative data and Big Data (more on: http://irevolution.net/2013/06/27/what-is-big-crisis-data/), eventually non-GIS data like texts, photos, videos, social media messages, represent a valid and cheap alternative to obtain useful information for crisis management and build scenarios. The main problems of non-authoritative data are that they can be produced by expert users, are not homogenous, are not validated; and can be misused. Other problems concern data quality, data accessibility, trust and credibility of the information and the supplier, privacy, intellectual property, security and crowd psychology. On the other hand, these data can be integrated with traditional sources, allowing the creation of high definition datasets with the collaboration of a huge number of users, and are timely and cost-effective.
Starting from the idea to extract useful information from non-authoritative data, the method designs a framework of application, rules, specifications on data, and create the representation of the footprint of an event. EDIT develops a new approach to emergency response applications, integrating a semantic reasoning into an event-based database system with usage of formal domain definitions. The methodology allows to make a semantic analysis starting from information contained in the web and categorizes results into a PostgreSQL scenario database containing significant disaster-related information (location, time and impacts). Accessing it, users can immediately query and visualize information on maps, for example using a QGIS environment. Data are enriched with the attribute of a semantic reliability index, introduced as a further filter for information.
EDIT is structured in many components and uses an operational tool based on Java for analyzing texts through Natural Language Processing (NLP) techniques, semantics and ontologies. To create the logical base of the procedure a concept map for disasters-related data has been created.
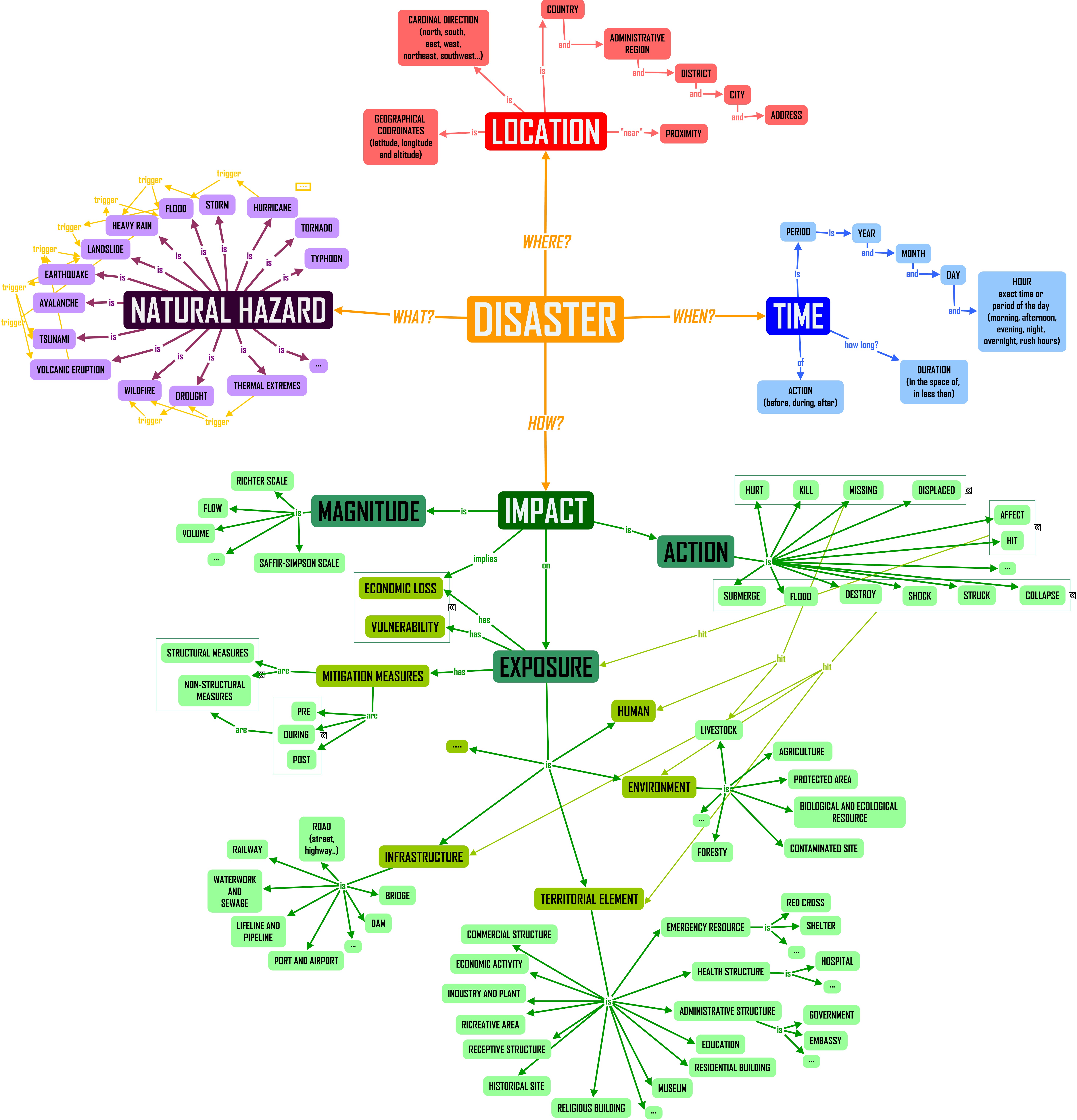
The semantic analysis is a fundamental step in the process of extraction from non-authoritative data: it is necessary to move from the natural language to a formal language and to populate the scenario database. Ontologies represent a solution to the semantic heterogeneity: the main aim of the ontology is trying to eliminate, or at least to reduce, conceptual and terminological confusion.
In order to extract relevant information from textual documents a Java code has been developed: it synthetizes the process of tokenization and bypass the POS tagging by comparing words contained in text with a list of keywords (the ones defined in the code lookup tables of EDIT database).
The meaningful elements are saved into a formal database structure that can be queried to obtain analysis results, which can be used for mapping, risk assessment, prediction, disaster real time response, damage evaluation, possible mitigation. The open source object-relational database management system PostgreSQL is chosen to realize the EDIT database for disaster representation: eighteen tables are created in order to contain all the relevant information; six of them are code lookup tables that contain glossary and thesaurus.
In order to add these “unconventional” information from multiple sources to a scenario is necessary the creation of a filter, both on the location – with the definition of a geographic location accuracy index – and on the content – with definition of a reliability index; after the filtering process, reliable information can be added for the construction of the scenario. Focusing on the reliability of data contents, some significant factors affect the quality of the information extraction, including: level of detail of the information, accuracy and precision of the information, correctness and completeness of a sentence, conformity to the reality, truthfulness of information, quantity of similar information, characteristics and reputation of the sources, expertise of providers, use of the information, subjectivity of the information. A semantic reliability index is created by taking into account the distinct components of the information.
A challenge for natural language processing is represented by online conversational text, exemplified by microblogs, chat, and text messages. Conversational text contains many nonstandard lexical items and syntactic patterns as a result of unintentional errors, dialectal variation, conversational ellipsis, topic diversity, and creative use of language or orthography. Applying EDIT Java code to the content of the tweet message it is possible to extract relevant news; in addition, selection of relevant words can be put in evidence considering ash tags. For researches on Twitter the integration with the AIDR tool has been considered. The free and open source Artificial Intelligence for Disaster Response (AIDR) platform leverages machine learning to automatically identify informative content on Twitter during disasters. It is under development by Qatar Computing Research Institute (more on: http://irevolution.net/2013/10/01/aidr-artificial-intelligence-for-disaster-response/).
Download the EDIT poster!!! —> EDIT_poster
